Transfering Simulated Learning to Real Robots
Lately, Robotics has become a major playfield for Reinforcement Learning. Learning-based algorithms have the potential to enable robots to acquire complex behaviors adaptively in unstructured environments by leveraging data collected from the environment. In particular, with reinforcement learning, robots learn novel behaviors through trial and error interactions. This unburdens the human operator from having to pre-program accurate behaviors. This is particularly important as we deploy robots in scenarios where the environment may not be known.
However, not only is training in the real world very time-consuming, it also puts the robots and the environment at considerable risk. To evade these problems, training in simulation and then transferring to the real is becoming a popular strategy. Training in simulation can lead to substantial speed-ups because of the possibility of parallelization without any significant extra costs.
But these models trained in simulation suffer from what is termed as the Reality Gap. This reality gap might arise because of multiple reasons such as omitting some physical phenomena, having inaccurate parameterized values of physical quantities or even small numerical approximations in typical solvers. One can argue that ideally all of these could be solved by building more accurate simulators, but that’s easier said than done. Moreover, the real world itself is non-stationary!
Our project deals with exploring methods to reduce this sim2real gap and deploy a model trained to do the Reach task in simulation on a real Xarm7 robot. Our goal is to deploy the model in the real world, with nothing but images as the current state input.
Training Setup
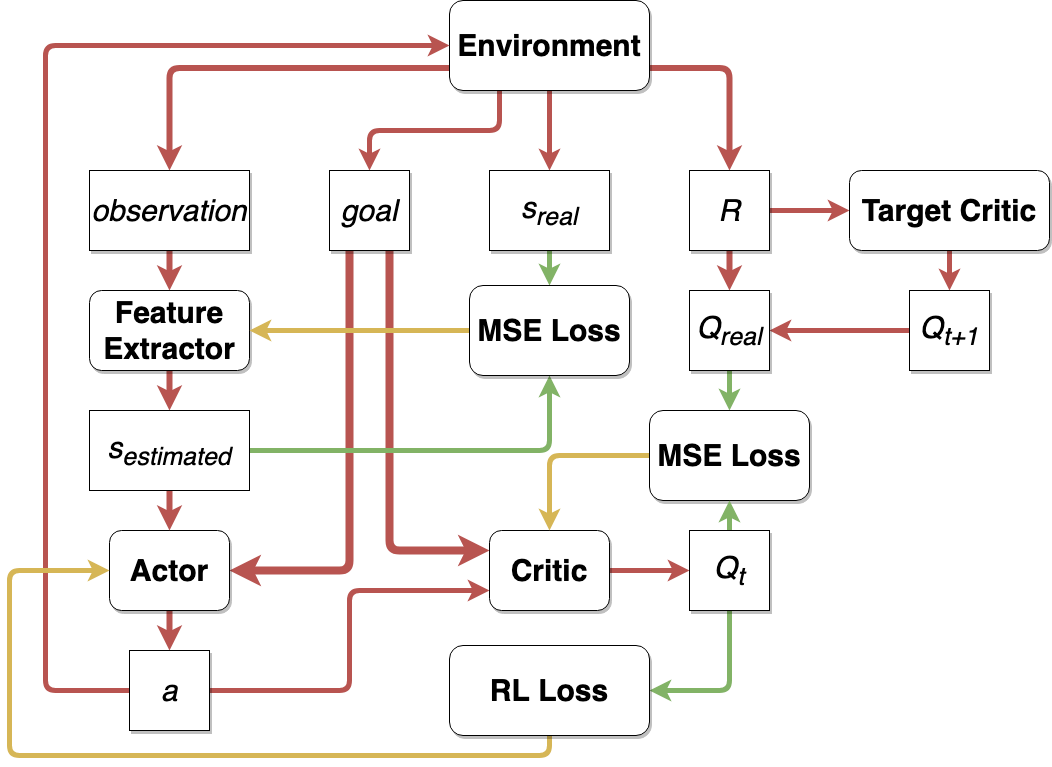
We use Mujoco for simulating our environment and depicted the real robot setup in terms of color and camera position as closely as possible. Training in simulaiton provides many advatages. The most important amongst those is access to state variables instead of just the images. This allows us to speed up training by using Asymmetric Actor Critic model. The Asymmetric Actor Critic uses a DDPG based approach, where the Actor gets image-based inputs but the Critic at the time of training gets state-based input.
Feature Extractor
We use a 3-layer Conv network to extract the current state (a 3D coordinate of the end effector’s position) from the Current state image (84x84x3) input. It is this state estimation using the feature extractor that is passed to the Actor in Test and Training time. Besides the RL loss that is backpropagated by the Actor Network, we also add an additional loss called the Bottleneck loss on the feature extractor to speed up training. The Bottleneck loss minimizes the difference between the actual state (which we get at the time of training) and the predicted loss by the feature extractor.
The loss function for the feature extractor looks something like-
\[L_f = L_{RL} + MSE(s,s_{predicted})\]The Bottleneck loss also led to significant speed gains in training the feature extractor.
Actor Network
The Actor takes in the predicted current state output from the feature extractor and the goal as a 3D coordinate as input, and outputs a 3D vector equivalent of the displacement in the 3D space. The actor optimizes on the loss-
\(L_a = -E_s[Q(s,\pi(s))]\) Where \(Q(s,\pi(s))\) is the estimated Q-value by the Critic. During deployment we only use the output of the actor.
Critic Network
The Critic takes in the action yielded by the Actor along with the current state as a 3D coordinate of the end effector and the goal as a 3D coordinate as input. It outputs the predicted Q-value of the action given the current state and goal as a single float value. The critic tries to optimize over the following loss function-
\[L_c = ( Q(s_t,a_t) - r_t - \gamma Q_T(s_{t+1},\pi(s_{t+1}) ) )^2\]Here the \(Q_T\) is predicted using the Target networks (Actor and Critic) which are updated using Polyak averaging of the weights of the corresponding current Actor and Critic networks.
Adapting to the Real World
Here, we discuss the optimizations we made during training and deployment time to bridge the sim2real gap.
Getting Past the Curse of Depth
Sometimes it is hard to gather Depth perception from plain images which leads to performance dips in the model in simulation and in the real world. In an ideal scenario, we would have liked to have additional information on depth. Depth is easy to gather in simulation. The real world on the hand was a different case. We tried using the Depth output of the Intel Realsense cameras, but much to our dismay it lacked the consistency and accuracy required for our model to work properly.
Here’s the juxtaposition of the depth information yielded by the simulation and the real world-
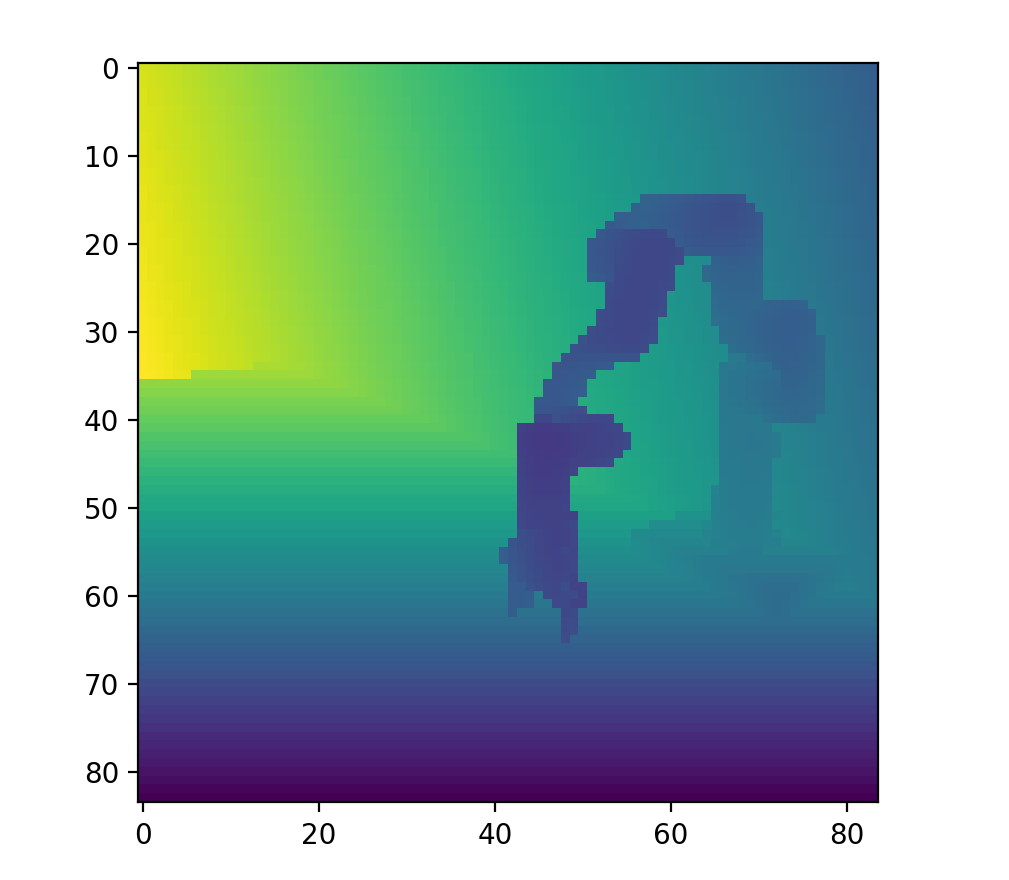
Looking at these results we decided move away from depth information altogether.
Fortunately we noticed that using a side camera angle allowed a more reasonable perception of depth. This is probably because the model has parameters such as the extension of the arm to latch onto to better estimate depth.

Domain Randomisation
The idea of Domain Randomization is based on the idea of generalisation. There are certain attributes of the simulation that might not perfectly mimic the real world leading to the sim2real gap. Randomising these attributes during training should develop resilience in the model to the corresponding variations in the real world.
If handled cavalierly, Domain Randomisation could lead to an unreasonable increase in training time or in worst case scenarios not train at all.
After a lot of trails, we settled on the following forms of Domain Randomisations for every episode-
- Camera angle variation: Here we vary the camera angle slightly to compensate for slight discrepancy in camera positioning in the real world.
- Lighting variation: Here we randomise the lighting in the simulation. This leads to resilience in the reflective and slight color variations in the real world.
Expriments with different setups
Best Results- Fully RL-based + Bottleneck + Initialized Feature extractor, no depth information
Since the depth information is too messy in real world to provide a good estimation of distance for the robot, we decided not to use the depth channel from the camera RealSense2. Trained
From this video we can see that the performance of the robot is pretty good, and the final gestures are really good mimics of what is shown in the simulation located at the bottom left corner. However, due to the size of the input images(\(84\times 84\)) differs from the frame size captured by RealSense2 Camera, sometimes the robot gripper can get out of the frame range of RealSense2 Camera and the model no longer knows where the gripper is. Thus when the target is generated really low and close to the came, this reach task will fail. Also, when the whole body of the robot vertically faces the camera frame, the model loses its precision for estimating the distance information and the configuration of the robot, which inevitably leads to failure. Nonetheless, if a new target is generated in a “good area”(good area means the area where the camera captures the side view of the robot almost all the time and the gripper will not get out the camera frame.), the model can surprisingly guide the robot gripper leave the blind area and go to the new target.
Fully RL-based, No Bottleneck, No Depth, No Initialized Feature Extractor
In this scenerio, both the view of angle and the position of the camera are changed to test the ability of the model trained by our domain randomization strategy to generalize among different views.
From the video we know that although the results are not that good compared with our best model, it still shows some capability to optimize for different views which can compensate a lot for the errors when attempting to replicate the configurations in the simulator. However, this model shares the same problem with the best model–the gripper can get out of the camera frame and the model loses the distance information and the estimation of the robot configuration.
RL-based + Initialized Feature Extractor + Depth Information, No Bottleneck
In this experiment, we want to know how much performance can be affected by the real world depth information. Here’s the result:
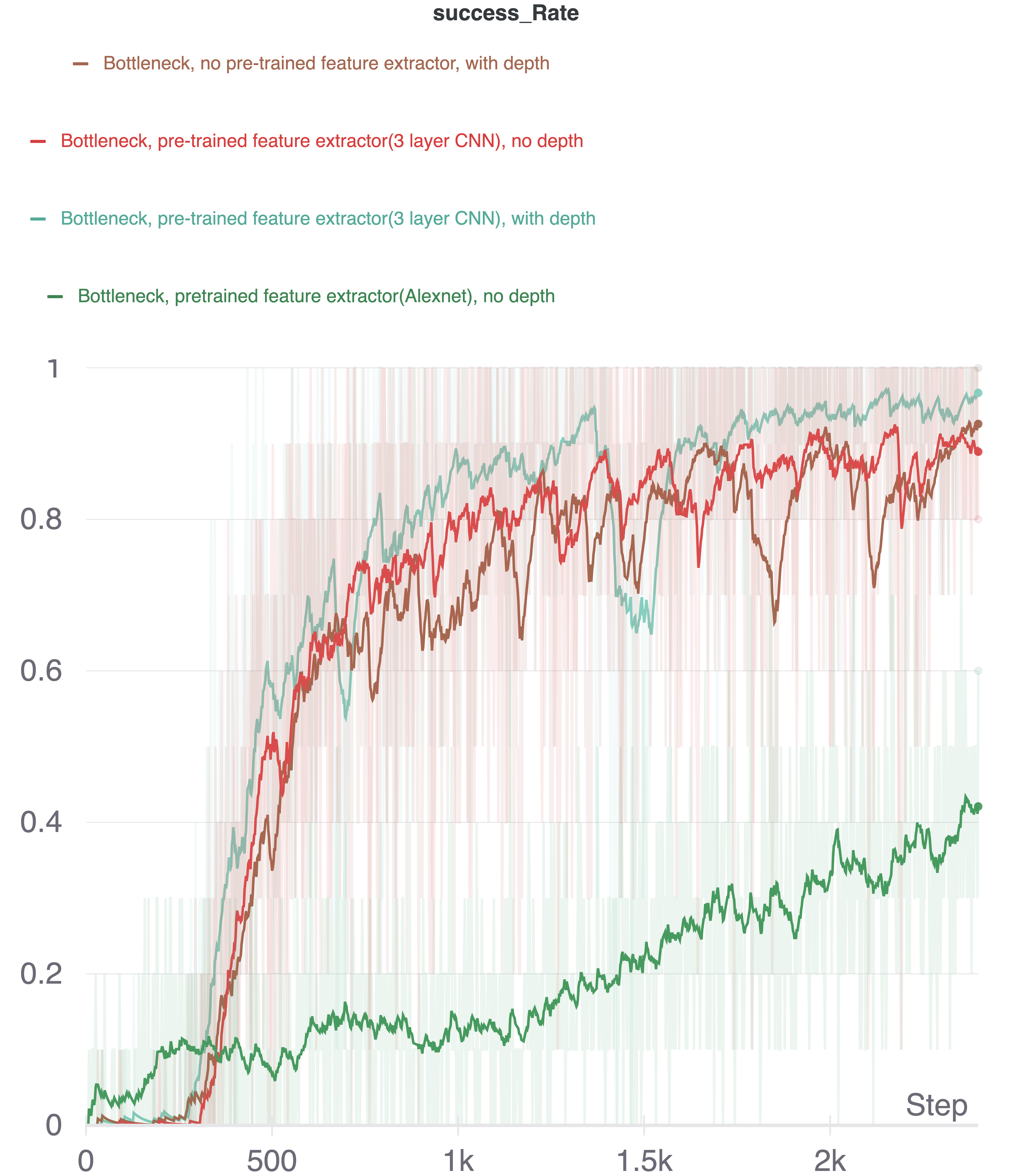
During the training time, with the boost of pre-trained feature extractor, the performance of the model in the training time is very good, and converges faster than the models which don’t have pre-trained feature extractor. However, when the model is transferred into real world, the depth information sabotages the performance of the model. As demonstrated in the video, when the gripper reaches into the overlay area of the corner of the curtain and the gripper from the view angle of the camera, despite a perfect side view in our eyes, the model completely lost its conception of the world and starts to do some random moves with no underlying logic.
Training time performance
In our experiments, we can show that the performance of the model (our best model + depth information) actually does better than our best model. Sadly the chaotic depth image from RealSense2 camera ruined everything. We also tried to use AlexNet as the feature extractor which is shown in the dark green curve. From this we know that the pre-trained AlexNet can only do better at the beginning of the training, and in later stages, its performance is climbing slowly and it takes more time to train if we want to achieve similar performance with a 3-layer CNN feature extractor.
Future works
- Our ultimate goal is to train the robot to do Pick & Place task. However, this model takes days to train and we never managed to transfer the model to real world though it is doing a great job in the simulator.
- We want to use more cameras to feed the feature extractor with multiple images from different angles so that the model can get a better estimation of the distance and the configuration of the robot without getting depth information involved and that also the model won’t be befuddled and bewildered when the robot is directly facing the camera frame and the whole body is almost vertical to the plane of the camera frame.